Announcing Supermetal Apache Iceberg Target
Single process CDC to Iceberg V3 with variant type. Compatible with S3 Tables, R2, Glue, and REST catalogs.
Supermetal now replicates transactional databases directly into Iceberg tables.
CDC updates and deletes are handled automatically so query engines always return the current state. Tables are created as Iceberg V3 with variant type by default. It works with S3 Tables, Cloudflare R2, Glue, and REST catalogs across all Supermetal source connectors including Postgres, MySQL, MongoDB, SQL Server, and Oracle.
Under the hood, a single Rust binary reads the database WAL, converts to Arrow columnar format, writes Parquet files to object storage, and commits to your Iceberg catalog. No Kafka, no Spark, no Flink. You can sync Postgres to S3/R2 and query it with DuckDB in minutes.
Single Process Ingestion
The typical Iceberg CDC ingestion pipeline involves multiple components:
┌───────────┐ ┌───────────┐ ┌───────────┐ ┌─────────────┐ ┌──────────────┐
│ Source DB │ ──► │ Debezium │ ──► │ Kafka │ ──► │ Flink/Spark │ ──► │ Iceberg (S3) │
└───────────┘ └───────────┘ └───────────┘ └─────────────┘ └──────────────┘
(JVM) (Message Broker) (Compute Cluster)Every row passes through multiple serialization cycles. Debezium reads the WAL, serializes each change to Avro or JSON, and writes to Kafka. The stream processor deserializes, transforms, and re-serializes to Parquet before committing to Iceberg. For wide tables with millions of rows, this per-message CPU cost adds up.
Supermetal handles the entire data path from WAL to committed Iceberg table in a single process:
┌───────────┐ ┌─────────────────┐ ┌──────────────┐
│ Source DB │ ──► │ Supermetal │ ──► │ Iceberg (S3) │
└───────────┘ └─────────────────┘ └──────────────┘
(Single Process)WAL events are decoded directly into columnar Arrow record batches and written as Parquet to object storage. There is no per-message serialization step and no intermediate message broker. Data flows from source to Parquet in a single process using the same columnar format end to end.
V3 and Variant
Supermetal creates V3 tables by default. Most ingestion tools still target V1 or V2.
V3 is the latest Iceberg spec. It adds the variant type for semi-structured data, along with deletion vectors and row-level lineage tracking.
Storing semi-structured data in data lakes typically means one of three compromises: flatten into a fixed schema, store as a JSON string and parse at query time, or create wide tables full of nullable columns. Variant encodes semi-structured data natively in Parquet's binary variant format, giving query engines columnar access to nested fields without a fixed schema.
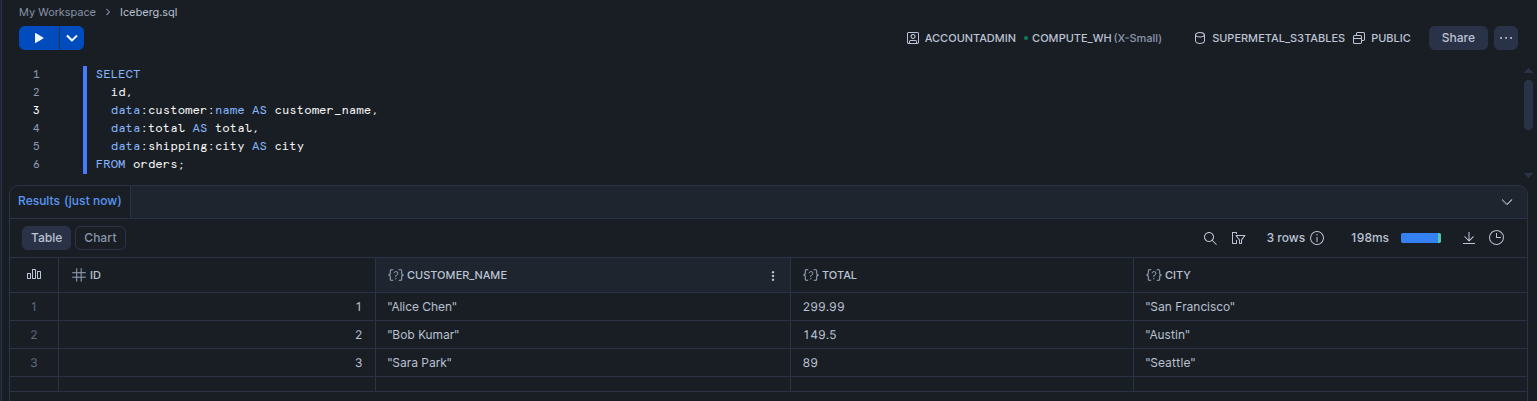
Supermetal automatically maps Postgres JSONB, MySQL JSON, and MongoDB documents to the Iceberg variant type.
CREATE TABLE orders (id serial PRIMARY KEY, data jsonb);
INSERT INTO orders VALUES
(1, '{"customer": {"name": "Alice Chen", "email": "[email protected]"}, "total": 299.99, "shipping": {"city": "San Francisco", "state": "CA"}}'),
(2, '{"customer": {"name": "Bob Kumar", "email": "[email protected]"}, "total": 149.50, "shipping": {"city": "Austin", "state": "TX"}}'),
(3, '{"customer": {"name": "Sara Park", "email": "[email protected]"}, "total": 89.00, "shipping": {"city": "Seattle", "state": "WA"}}');After replication, the same data is queryable as native variant columns:


Write Modes
Supermetal supports two write modes for CDC operations.
Merge on Read
┌──────────────┐ ┌─────────────────────┐ ┌──────────────────────────────────────────────────┐
│ CDC Records │ │ Supermetal │ │ s3://bucket/warehouse/db.orders/ │
│ │ WAL Stream │ │ Commit │ │
│ • INSERT │ ──────────────►│ • Arrow batches │ ──────────────►│ ├── data/ │
│ • UPDATE │ │ • Position tracking │ │ │ ├── _sm_01965a3b.parquet (data) │
│ • DELETE │ │ • Eq delete writer │ │ │ ├── eq_del_01965a3c.parquet (eq delete) │
└──────────────┘ └─────────────────────┘ │ │ ├── pos_del_01965a3d.parquet (if duplicates) │
│ │ └── dv_01965a3e.puffin (if duplicates) │
│ └── metadata/ │
│ ├── v1.metadata.gz.json │
│ └── snap-01965a3f.avro │
└──────────────────────────────────────────────────┘Updates and deletes write equality delete files alongside new data files. Query engines merge them at read time. Equality deletes mask older versions of a row across batches. When the same primary key appears more than once in a single flush, Supermetal writes deletion vectors (V3) or position delete files (V2) to handle the intra-batch duplicates.
Merge on Read requires V2 or V3 and a query engine that supports equality deletes (Spark 3.x+, Trino, Dremio, Snowflake, StarRocks).
Append
In Append mode, every CDC operation (insert, update, delete) appends a new row. The current state of each row is tracked via metadata columns _sm_deleted and _sm_version. To query the latest state, filter with WHERE _sm_deleted = false and deduplicate by primary key on _sm_version. Append works with any Iceberg version and any query engine.
Correctness
Supermetal prioritizes correctness above all. Our testing includes end-to-end type fuzzing from source to target and sqllogictest style test suites.
Type fuzzing generates randomized values for each source database type, biasing edge cases and boundary values. Our sqllogictest suites validate snapshots, CDC, and schema evolution for every connector.
We run source databases through Supermetal into Iceberg tables, then use DuckDB's Iceberg extension to read the resulting tables and assert the replicated data matches the source exactly.
Performance
Benchmark: Postgres to Iceberg
TPC-H SF10 dataset (86.6M rows across 8 tables) replicated from Postgres to Iceberg with a REST catalog and MinIO object storage.
Latency under 3s up to 25K rows/sec with flush interval set to 1s (default is 10s). Above 25K/sec, single-threaded Postgres logical decoding saturates. The Breakdown view shows Read Latency dominates at higher throughput levels.
Watch out for upcoming comparison benchmarks against Spark and Flink ingestion pipelines.
Get started in minutes
curl -fsSL https://trial.supermetal.io/install.sh | shiwr -useb https://trial.supermetal.io/install.ps1 | iex